
Преди десет години д-р Джеф Лихтман - професор по молекулярна и клетъчна биология в Харвардския университет, получава малка мозъчна проба в своята лаборатория.
Макар и малък, 1 кубичен милиметър тъкан е достатъчно голям, за да съдържа 57 000 клетки, 230 милиметра кръвоносни съдове и 150 милиона синапса.
„Беше по-малко от оризово зърно, но започнахме да го режем и да го разглеждаме и беше наистина красиво“, казва професорът.
„Но докато натрупвахме данните, осъзнах, че просто разполагаме с много повече, отколкото можем да понесем.“
В крайна сметка, Лихтман и неговият екип стигат до 1400 терабайта данни от извадката - приблизително съдържанието на над 1 милиард книги. Сега, след десетилетие на тясно сътрудничество на лабораторния екип с учени от Google, тези данни се превръщат в най-подробната карта на проба от човешки мозък, създавана някога.
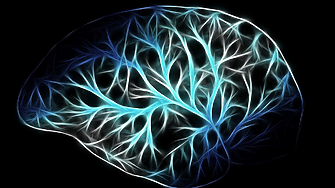
300 милиона изображения
Мозъчната проба идва от пациент с тежка епилепсия. Това е стандартна процедура, казва Лихтман, да се премахне малка част от мозъка, за да се спрат гърчовете, и след това да се изследва тъканта, за да се уверят учените, че е нормална. Професорът обаче не знае нищо по-конкретно за пациента, освен неговата възраст и пол.
За да анализират пробата, Лихтман и неговият екип първо я нарязват на тънки части с помощта на нож с диамантено острие. След това фрагментите са вградени в твърда смола и нарязани отново много тънко.
„Около 30 нанометра, или приблизително 1000 от дебелината на човешкия косъм. Те бяха практически невидими, ако не беше фактът, че ги бяхме оцветили с тежки метали, което ги направиха видими при правене на електронни изображения“, казва ученият.
В крайна сметка, екипът получава няколко хиляди резена, създавайки нещо като филмова лента: ако направите снимка на всяка от тези секции и подравните тези снимки, ще получите триизмерно парче на мозъка на микроскопично ниво.
Тогава изследователите осъзнават, че се нуждаят от помощ с данните, тъй като получените изображения заемат значително количество място за съхранение.
Лихтман знае, че Google работи върху цифрова карта на мозъка на плодова мушица, публикувана през 2019 г., и разполага с правилния компютърен хардуер за това. Той се свързва с Вирен Джейн - старши научен сътрудник в Google, който работи по проекта с плодовата муха.
„Имаше 300 милиона отделни изображения (в данните на Харвард)“, казва Джейн. „Това, което ги прави толкова много, е изобразяването с много висока резолюция, нивото на индивидуален синапс. И само в тази малка проба от мозъчна тъкан има 150 милиона синапса“.
За да осмислят изображенията, учените от Google използват базирана на изкуствен интелект обработка и анализ, идентифицирайки какъв тип клетки има във всяка снимка и как са свързани. Резултатът е интерактивен 3D модел на мозъчната тъкан и най-големият набор от данни, правен някога при тази резолюция на човешка мозъчна структура.
Google го прави достъпен онлайн, като по същото време е публикувано проучване в списание Science, на което Лихтман и Джайн са съавтори.

Разбиране на мозъка
Сътрудничеството между екипите на Харвард и Google води до цветни изображения, които правят отделните компоненти по-видими, но иначе са вярно представяне на тъканта.
„Цветовете са напълно произволни“, обяснява Джейн, „но няма много артистична свобода. Целият смисъл на това е, че ние не си измисляме - това са истинските неврони, истинските „жици“, които съществуват в този мозък, и ние наистина го правим удобен и достъпен за биолозите да го разглеждат и изучават“.
Данните съдържат някои изненади. Например, вместо да образуват една връзка, двойките неврони имат повече от 50.
„Това е като две къщи в блок да имат 50 отделни телефонни линии, които ги свързват. Какво става там? Защо са толкова силно свързани? Все още не знаем каква е функцията или значението на това явление, ще трябва да го проучим допълнително“.
В крайна сметка, наблюдението на мозъка на това ниво на детайлност може да помогне на изследователите да осмислят неразгадани досега медицински състояния, според Лихтман.
„Какво означава да разберем нашия мозък? Най-доброто, което можем да направим, е да го опишем и да се надяваме, че от тези описания ще дойде осъзнаване, например, за това как нормалните мозъци са различни от мозъците, които са разстроени. При психиатрични заболявания или разстройства на развитието, като аутистичния спектър - този вид сравнение ще бъде много ценно“, казва ученият. „В крайна сметка, това ще ни даде известна представа какво не е наред, за което в повечето случаи все още сме ‘на тъмно’.“
Лихтман вярва, че наборът от данни може да е пълен с други невероятни подробности, които поради размера му все още не са открити:
„И затова го споделяме онлайн, така че всеки да може да го погледне и да намери нещо“.
След това екипът зад проекта има за цел да създаде пълна карта на мозъка на мишка, която ще изисква между 500 и 1000 пъти повече данни от пробата от човешкия мозък.
„Това би означавало 1 екзабайт, което е 1000 петабайта“, казва Лихтман. „Мисля, че би бил преломен момент за неврологията да има пълна схема на свързване на мозъка на бозайник - ще отговори на много, много въпроси. И разбира се, това ще разкрие много повече проблеми, неща, които не сме очаквали“.
Какво ще кажете за картографиране на цял човешки мозък? Това би било още 1000 пъти по-голямо, обяснява Лихтман, което означава, че данните ще възлизат на 1 зетабайт.
През 2016 г. това беше размерът на целия интернет трафик за годината, според Cisco. В момента, според Лихтман, не само би било трудно дори да се съхранят толкова много данни, но няма да има етично приемлив начин за намиране на добре запазен човешки мозък.
Новините на Darik Business Review във Facebook , Instagram , LinkedIn и Twitter !
Още по темата
- Министерството на туризма рекламира България като прохладната дестинация на Европа
- Цветомир Узунов, Kaufland България: Ритейлът вече е технологичен бизнес, който продава храна
- Битката за AI таланти: OpenAI привлече вицепрезидент на Google
- Проучване: Три икономически фактора оставят отпечатък върху детския мозък






Грижа по мярка при кастрирани котки
Калкулатори
Най-ново
София в борба с жегите: Раздават безплатна вода и оросяват 58 булеварда
преди 6 минИзбраха изпълнителя за обновяването на благоевградския парк „Бачиново“ за над 3 млн. евро
преди 15 минВМА въведе първата в България компютърна томография от ново поколение (снимки)
преди 25 минГърция замразява цените на 2000 основни продукта за два месеца
преди 52 минНедостиг на гориво в Русия: Кризата се разпространява от Крим до Москва след украински атаки
преди 58 минИсторически срив при златото: Цените записват най-големия месечен спад от близо 18 години
преди 1 часПрочети още
Тя обяви гладна стачка заради „Александровска“ болница! Говори проф. д-р Милена Иванова-Шиварова
darik.bgДоц. Инджов: Протести да свалят Радев? Засега няма как!
darik.bg„Моето дете в гроба не яде нищо!“ Николай Попов с предупреждения към Радев!
darik.bgДобре дошла, Джина! Втората дъщеричка на Мари Констанстин се роди
9meseca.bg